
با پیشرفت در فناوریهای نوین، متخصصان بیوانفورماتیک اکنون میتوانند از تجزیه و تحلیل کلان دادهها برای درک بهتر بیماریها نسبت به گذشته استفاده کنند. آنها همچنین میتوانند سیستمهای مولکولی بیماران را رمزگشایی کرده و درمانهای شخصیسازی شدهای ارائه دهند که عوارض جانبی منفی را به حداقل میرساند.
اما انجام چنین تحلیلهایی چقدر دشوار است؟
ماهیت گسترده و پیچیده دادههای اومیکس، دستیابی شرکتهای بیوتکنولوژی و داروسازی به نتایج قابل اعتماد را با استفاده از روشهای تحلیلی سنتی دشوار میسازد. بسیاری ترجیح میدهند برای ساخت یا سفارشیسازی ابزارهای تجزیه و تحلیل دادههای اومیکس، شرکتهای تحلیل داده را استخدام کنند.
بنابراین، دقیقاً "دادههای اومیکس" چیست؟ چرا رویکردهای تحلیلی سنتی در مواجهه با مجموعهدادههای اومیکس ناکام میمانند و هوش مصنوعی چگونه میتواند کمک کند؟ بیایید این موضوع را بررسی کنیم!
چرا رویکردهای سنتی در تجزیه و تحلیل دادههای اومیکس ناکافی هستند؟
پاسخ کوتاه این است که دادههای اومیکس دارای ویژگیهای منحصر به فردی هستند که مختص مجموعهدادههای بزرگ و چندبعدی است. این ویژگیها باعث ناکارآمدی تکنیکهای سنتی تحلیل داده میشوند. اما ابتدا، بیایید دادههای اومیکس را تعریف کرده و سپس به چالشهای مرتبط بپردازیم.
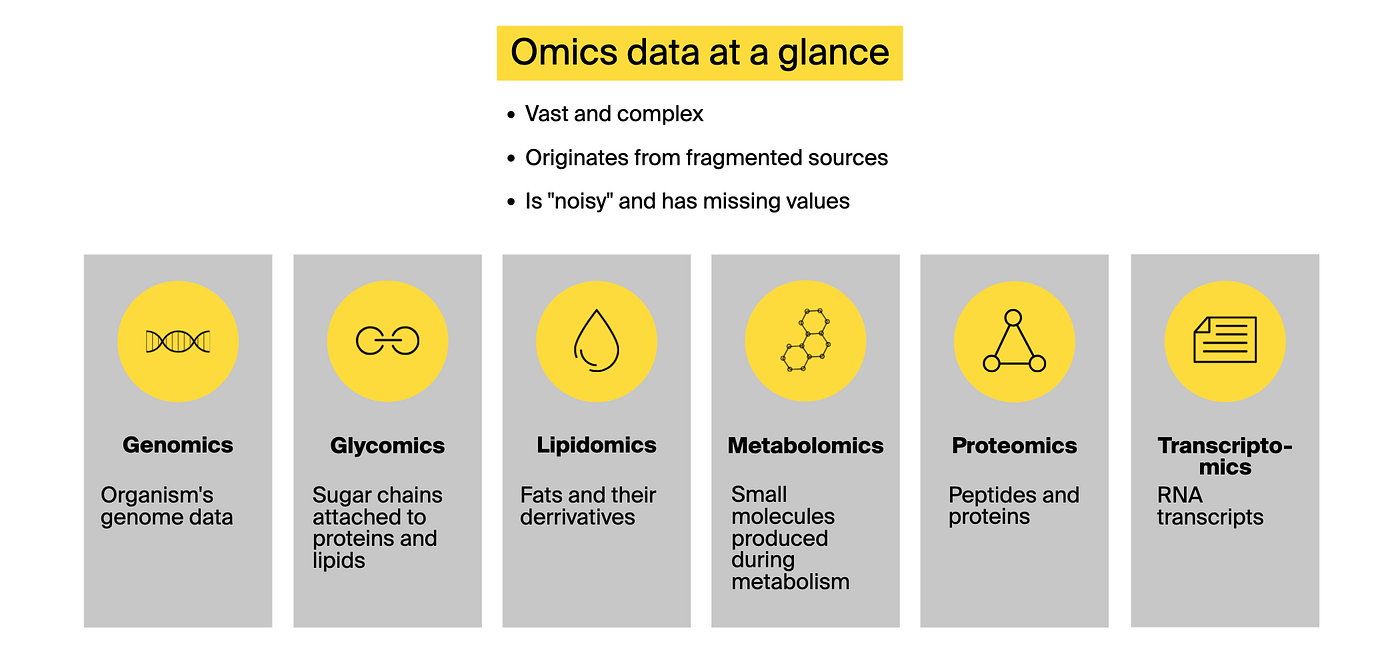
دادههای اومیکس چیست و چه چیزهایی را شامل میشود؟
دادههای اومیکس اطلاعاتی هستند که توسط فناوریهای مدرن در حین تجزیه و تحلیل نمونههای بیولوژیکی تولید میشوند. اومیکس نمای دقیقی از حیات در سطح مولکولی به ما میدهد. چنین دادههایی معمولاً توسط رشتههایی که با پسوند -اومیکس پایان مییابند، مانند:
- ژنومیکس (Genomics): مطالعه کل ژنوم یک موجود زنده
- ترنسکریپتومیکس (Transcriptomics): تمرکز بر رونویسیهای RNA و آشکار ساختن اینکه کدام ژنها در بافتهای مختلف یا تحت شرایط خاص فعالانه بیان میشوند.
- پروتئومیکس (Proteomics): کاوش پپتیدها و پروتئینها در یک موجود زنده، کمک به محققان برای درک فرآیندهای بیولوژیکی و مسیرهای سیگنالینگ.
- متابولومیکس (Metabolomics): بررسی مولکولهای کوچک (متابولیتها) تولید شده در طول متابولیسم برای تعیین وضعیت و پاسخهای متابولیکی یک موجود زنده.
- اپیژنومیکس (Epigenomics): تحقیق در مورد تغییرات DNA و هیستون که بیان ژن را بدون تأثیر بر کد اصلی کنترل میکنند.
- میکروبیومیکس (Microbiomics): مطالعه جامعه میکروارگانیسمهایی که در بدن انسان و روی آن زندگی میکنند، از جمله میکروبیوم روده.
- لیپیدومیکس (Lipidomics): همانطور که از نامش پیداست، تمرکز بر مطالعه لیپیدها - چربیها و مشتقات آنها - که نقش حیاتی در ذخیره انرژی، سیگنالدهی سلولی و ساختار غشاء دارند.
- گلیکومیکس (Glycomics): مطالعه زنجیرههای پیچیده قند که به پروتئینها و لیپیدها متصل هستند و برای ارتباط سلولی، پاسخ ایمنی و یکپارچگی ساختاری ضروری هستند.
اهمیت و پیچیدگی تجزیه و تحلیل دادههای اومیکس
دادههای اومیکس گسترده و پیچیدهاند، اما پتانسیل عظیمی دارند. با تجزیه و تحلیل دادههای اومیکس، محققان و پزشکان میتوانند نشانگرهای زیستی بیماری را کشف کنند، پاسخ بیماران به درمانها را پیشبینی کنند، برنامههای درمانی شخصیسازی شده طراحی کنند و موارد دیگر.
دادههای اومیکس بهطور خاص هنگام استفاده از رویکرد چند-اومیکس (Multi-omics) که چندین جریان داده را ترکیب میکند، مفید هستند. اکثر بیماریهای شایع، مانند آلزایمر و سرطان، چندعاملی هستند و تجزیه و تحلیل یک نوع داده اومیکس اثر درمانی یا پیشبینی محدودی خواهد داشت. این موضوع مدیریت دادههای چند-اومیکس را برای محققان به یک قابلیت ضروری تبدیل میکند، اما تحلیل را نیز پیچیده میسازد.
در اینجا دلیل چالشبرانگیز بودن مدیریت دادههای اومیکس با ابزارهای تحلیلی سنتی آورده شده است.
چالشهایی که نرمافزار تحلیل دادههای اومیکس ممکن است با آنها روبرو شود
چندین ویژگی وجود دارد که مانع از کارایی روشهای تحلیلی سنتی در برخورد با دادههای اومیکس، چه برسد به رویکردهای چند-اومیکس، میشود:
- پیچیدگی و حجم داده. مجموعهدادههای اومیکس، مانند دادههای ژنومیکس یا پروتئومیکس، اغلب شامل میلیونها نقطه داده برای یک نمونه منفرد هستند. روشهای سنتی برای مدیریت این فضای ویژگی وسیع با مشکل مواجه هستند و منجر به گلوگاههای محاسباتی میشوند.
- منابع داده تکهتکه. دادههای اومیکس از پلتفرمها، آزمایشها و مخازن متنوعی میآیند. قالبها، استانداردها و توضیحات دادهای مختلفی توسط گروههای تحقیقاتی یا مؤسسات مختلف استفاده میشود. ادغام این قالبهای داده در یک چارچوب تحلیلی منسجم میتواند برای رویکردهای سنتی دلهرهآور باشد.
- نویز و دادههای از دست رفته. آزمایشهای بیولوژیکی بهطور ذاتی دادههای نویزدار تولید میکنند که با خطاهای فنی و مقادیر از دست رفته تشدید میشود. ابزارهای تحلیلی سنتی فاقد سازوکارهای قوی برای مقابله با این نواقص هستند که منجر به نتایج مغرضانه یا نادرست میشود.
- پیچیدگی در تفسیر بیولوژیکی. تحلیلهای سنتی اغلب همبستگیها یا الگوهای آماری را در مجموعهدادههای اومیکس شناسایی میکنند اما نمیتوانند آنها را به بینشهای بیولوژیکی عملی ترجمه کنند. برای مثال، برای تعیین نقش یک نوع ژنی خاص در مسیر بیماری، ابزار باید دادهها را با دانش بیولوژیکی موجود، مانند پروفایلهای بیان ژن و تعاملات پروتئینی، ترکیب کند. ابزارهای سنتی تجزیه و تحلیل دادههای اومیکس بهطور معمول فاقد پیچیدگی لازم برای انجام چنین تحلیلهایی هستند.
چگونه هوش مصنوعی میتواند چالشهای کلیدی تجزیه و تحلیل دادههای اومیکس را حل کند
هوش مصنوعی و زیرمجموعههای آن تأثیر فوقالعادهای بر حوزههای داروسازی و بیوانفورماتیک دارند. ما لیستی از مقالات روشنگر در این زمینه را تهیه کردهایم:
- هوش مصنوعی و یادگیری ماشین برای بیوانفورماتیک
- هوش مصنوعی مولد در علوم زیستی: موارد استفاده
- هوش مصنوعی مولد برای بخش داروسازی
- کشف دارو با کمک هوش مصنوعی
- تأثیر هوش مصنوعی مولد بر کشف دارو
بیایید کشف کنیم که چگونه فناوری پیشرفته میتواند تجزیه و تحلیل دادههای اومیکس را سادهسازی کند.
مدیریت ابعاد بالا
مجموعهدادههای اومیکس اغلب حاوی میلیونها ویژگی هستند که روشهای تحلیلی سنتی را تحت تأثیر قرار داده و تعیین متغیرهای مرتبط را دشوار میسازند.
هوش مصنوعی در مدیریت چنین مجموعهدادههای بزرگی با شناسایی خودکار متغیرهایی که بیشترین اهمیت را دارند و نادیده گرفتن اطلاعات نامربوط یا اضافی از طریق بهکارگیری تکنیکهایی مانند کاهش ویژگی، برتری دارد. هوش مصنوعی با تمرکز بر مهمترین الگوها و ارتباطات، تجزیه و تحلیل دادههای اومیکس را ساده میکند و به محققان کمک میکند تا بینشهای کلیدی را بدون گم شدن در پیچیدگی دادهها کشف کنند.
ادغام دادههای ناهمگون
دادههای متنوعی که توسط رشتههای اومیکس، مانند ژنومیکس، پروتئومیکس و متابولومیکس تولید میشوند، چالشبرانگیز هستند تا بهطور منسجم ادغام شوند.
مدلهای هوش مصنوعی میتوانند دادههایی را که در قالبهای مختلف میآیند، مانند توالیهای ژنومی و پروندههای بالینی، استانداردسازی کرده و نرمالسازی کنند تا از سازگاری اطمینان حاصل شود. سپس دادهها توسط الگوریتمهای هوش مصنوعی پردازش میشوند تا روابط بین مجموعهدادهها را آشکار سازند و نشان دهند که چگونه تغییرات در یک لایه اومیکس بر لایه دیگر تأثیر میگذارد.
بهعنوان مثال، ابزارهای هوش مصنوعی میتوانند دادههای ژنومی، مانند جهشهای ژنی، را با دادههای پروتئومیکس، مانند سطوح بیان پروتئین، ترکیب کنند تا سرطان را بهتر درک کنند. با پیوند دادن این دو نوع داده، هوش مصنوعی میتواند به شناسایی چگونگی تغییرات ژنتیکی در سلولهای تومور منجر به تغییرات در رفتار پروتئین، توضیح نحوه توسعه سرطان و پیشنهاد اهداف جدید برای درمان کمک کند.
پرداختن به نویز و اطلاعات از دست رفته
دادههای نویزدار و مقادیر از دست رفته میتوانند روشهای تحلیل سنتی را منحرف کنند.
برای غلبه بر این موانع، هوش مصنوعی از الگوریتمهای پیشرفته مانند imputation و کاهش نویز استفاده میکند. نرمافزار تجزیه و تحلیل دادههای اومیکس مبتنی بر هوش مصنوعی الگوهای موجود در مجموعهدادههای کامل را برای تخمین مقادیر از دست رفته با دقت بالا شناسایی میکند. بهعنوان مثال، اگر بیان ژن خاصی ثبت نشده باشد، هوش مصنوعی ممکن است مقدار آن را بر اساس ژنهای مشابه یا الگوهای موجود در دادههای اطراف پیشبینی کند. تکنیکهایی مانند شبکههای تولیدکننده متقابل (GANs) میتوانند نقاط داده واقعبینانه تولید کنند تا خلاها را پر کنند. ابزارهای هوش مصنوعی همچنین میتوانند سیگنالهای نامربوع یا نویزدار، مانند دادههای پرت و نوسانات تصادفی را فیلتر کنند.
برای نمونه، یک تیم تحقیقاتی کرهای ابزار نوآورانه مبتنی بر هوش مصنوعی را پیشنهاد کرد که از padding برای کار با مجموعهدادههای اومیکس ناقص استفاده میکند و بهطور صحیح انواع سرطان را شناسایی میکند. این ابزار دو بخش دارد - یک مدل هوش مصنوعی مولد که میتواند الگوهای ژنتیکی تومور را یاد بگیرد و padding را برای جایگزینی نقاط داده از دست رفته با مقادیر مجازی اعمال کند و یک مدل طبقهبندی که دادههای اومیکس را تجزیه و تحلیل کرده و نوع سرطان را پیشبینی میکند. محققان این ابزار را آزمایش کرده و گزارش دادند که این ابزار فنوتیپهای سرطان را بهطور مؤثر طبقهبندی میکند، حتی هنگام کار با مجموعهدادههای ناقص.
افزایش دقت و کارایی
فرآیندهای سنتی بهشدت به انسانها متکی هستند که آنها را مستعد خطا، زمانبر و ناکارآمد برای تحلیلهای در مقیاس بزرگ میسازد.
هوش مصنوعی با خودکارسازی وظایف حیاتی و بهبود دقت، فرآیند را متحول میکند. بهجای پیشپردازش دستی، فیلتر کردن، تجزیه و تحلیل و تفسیر مجموعهدادههای عظیم، ابزارهای هوش مصنوعی میتوانند این کار را بهصورت خودکار و با دقت بسیار بیشتری انجام دهند. برای مثال، هوش مصنوعی میتواند بهسرعت هزاران ژن، پروتئین یا متابولیت را اسکن کند تا آنهایی را که با یک بیماری خاص بیشترین ارتباط را دارند، مشخص کند. همچنین میتواند ناهنجاریها را شناسایی کند، مانند الگوهای غیرمعمول و دادههای پرت، و این ناسازگاریها را علامتگذاری کند تا از سوگیری در بینشهای تحلیلی جلوگیری کند.
مطالعات بالینی این ایده را تأیید میکنند که هوش مصنوعی میتواند در تشخیص سرطان دقیقتر از پزشکان انسانی باشد. یک آزمایش اخیر نشان میدهد که Unfold AI - نرمافزار بالینی ساخته شده توسط Avenda Health و تأیید شده توسط FDA - میتواند سرطان پروستات را از مجموعهدادههای بالینی مختلف با دقت ۸۴٪ شناسایی کند، در حالی که پزشکان انسانی در کار با همان دادهها تنها به دقت ۶۷٪ دست یافتند.
حتی عوامل هوش مصنوعی خودکار وجود دارند که با حداقل دخالت انسانی از تجزیه و تحلیل دادههای چند-اومیکس مراقبت میکنند. تجزیه و تحلیل بیوانفورماتیک خودکار (AutoBA) یکی از این نمونههاست. این عامل هوش مصنوعی از مدلهای زبانی بزرگ (LLMs) برای برنامهریزی و انجام تحلیلهای دادههای اومیکس استفاده میکند. ورودی کاربر محدود به وارد کردن مسیر داده، توضیحات و هدف نهایی محاسبات است. AutoBA سپس فرآیند را بر اساس مجموعهدادههای ارائه شده طراحی میکند، کد تولید میکند، آن را اجرا میکند و نتایج را نمایش میدهد.
بهبود قابلیت تفسیر و تصمیمگیری
تکنیکهای تحلیل داده سنتی، و همچنین بسیاری از مدلهای هوش مصنوعی، اغلب مانند "جعبه سیاه" عمل میکنند، نتایجی را ارائه میدهند که تفسیر یا توضیح آنها دشوار است. محققان توصیهها یا پیشبینیها را میبینند اما دلیل تصمیم سیستم را نمیفهمند.
هوش مصنوعی میتواند این مشکل را از طریق تکنیکهای هوش مصنوعی قابل توضیح (XAI) حل کند، که نتایج پیچیده را شفافتر و آسانتر برای درک میسازند و نشان میدهند که مدل چگونه به نتایج خود رسیده است. بهعنوان مثال، هوش مصنوعی میتواند مشخص کند کدام ژنها، پروتئینها یا عوامل دیگر در پیشبینی بیماری یا طبقهبندی نمونهها بیشترین تأثیر را داشتهاند. ابزارهای بصری، مانند نقشههای حرارتی، رتبهبندی ویژگیها یا نمودارهای شبکه، میتوانند به محققان کمک کنند تا بهوضوح روابط و منطق پشت خروجی مدل را ببینند.
یکی از نمونههای ابزار تجزیه و تحلیل دادههای اومیکس مبتنی بر هوش مصنوعی قابل توضیح، AutoXAI4Omics است. این نرمافزار متنباز وظایف رگرسیون و طبقهبندی را انجام میدهد. میتواند دادهها را پیشپردازش کرده و مجموعه بهینه ویژگیها و مناسبترین مدل یادگیری ماشین را انتخاب کند. AutoXAI4Omics تصمیمات خود را با نمایش ارتباطات بین ویژگیهای دادههای اومیکس و هدف تحت تحلیل توضیح میدهد.
نکاتی که هنگام پیادهسازی هوش مصنوعی برای تجزیه و تحلیل دادههای اومیکس باید در نظر گرفت
برای پیادهسازی موفقیتآمیز تجزیه و تحلیل دادههای اومیکس با پشتیبانی هوش مصنوعی، عوامل زیر را قبل از شروع پیادهسازی در نظر بگیرید.
کیفیت داده
الگوریتمهای هوش مصنوعی بر دادههای با کیفیت بالا رشد میکنند و در اومیکس، بینشها تنها به اندازه مجموعهدادهها دقیق هستند. پس از جمعآوری دادهها با استفاده از جمعآوری خودکار داده یا دستی، مجموعهداده را بهگونهای پیشپردازش کنید که برای مصرف هوش مصنوعی مناسب باشد.
برای تجزیه و تحلیل دادههای چند-اومیکس، شما منابع داده مختلفی مانند ژنومیکس، پروتئومیکس و متابولومیکس را ترکیب خواهید کرد که نیاز به حل ناهماهنگیها در فرمتها و استانداردهای داده خواهد داشت. اگر هنوز این کار را انجام ندادهاید، وقت آن است که در روشهای قوی حاکمیت داده سرمایهگذاری کنید.
در ITRex، ما مشاوران داده باتجربه داریم که به شما در تدوین یک استراتژی داده سازمانی مؤثر و ایجاد یک چارچوب مدیریت داده محکم برای پشتیبانی از ابتکارات هوش مصنوعی شما کمک خواهند کرد. ما همچنین میتوانیم در زمینه ذخیرهسازی دادهها و مشاوره در مورد گزینههای انبار داده به شما یاری رسانیم.
اخلاق و انطباق با مقررات
دادههای اومیکس اغلب حاوی اطلاعات حساسی هستند که از نظر قانونی محافظت میشوند، زیرا میتوانند برای کشف هویتها استفاده شوند. برای مثال، سطوح بیان پروتئین در پلاسمای خون در برخی موارد برای شناسایی افراد کافی است. وقتی هوش مصنوعی را به این ترکیب اضافه میکنید، نگرانیهای مربوط به حریم خصوصی بیشتر میشوند. تحقیقات نشان میدهند که در طول فاز آموزش مدل امکان استنباط هویت بیمار وجود دارد. حتی پس از پایان آموزش، هنوز پتانسیل حملات هکرها به مدل و استخراج اطلاعات خصوصی وجود دارد.
برای انطباق با استانداردهای اخلاقی، رضایت آگاهانه از شرکتکنندگان در مطالعه را دریافت کرده و اطمینان حاصل کنید که الگوریتمهای هوش مصنوعی تعصبات یا شیوههای ناعادلانه را ادامه نمیدهند.
اگر با ITRex همکاری کنید، ما از مدیریت شفاف دادهها و مستندسازی روشن فرآیند برای ایجاد اعتماد با تمام طرفهای درگیر اطمینان حاصل خواهیم کرد. ما به شما کمک میکنیم هوش مصنوعی قابل توضیح را پیادهسازی کنید تا محققان بتوانند نحوه رسیدن الگوریتمها به توصیهها را درک کرده و صحت آنها را تأیید کنند. همچنین سیستم هوش مصنوعی شما را برای آسیبپذیریهای امنیتی بررسی خواهیم کرد. و البته، تیم ما به چارچوبهای نظارتی مانند مقررات عمومی حفاظت از دادهها (GDPR)، قانون قابلیت حمل و پاسخگویی بیمه سلامت (HIPAA) و سایر مقررات محلی مرتبط پایبند است تا از حریم خصوصی و امنیت دادهها محافظت کند.
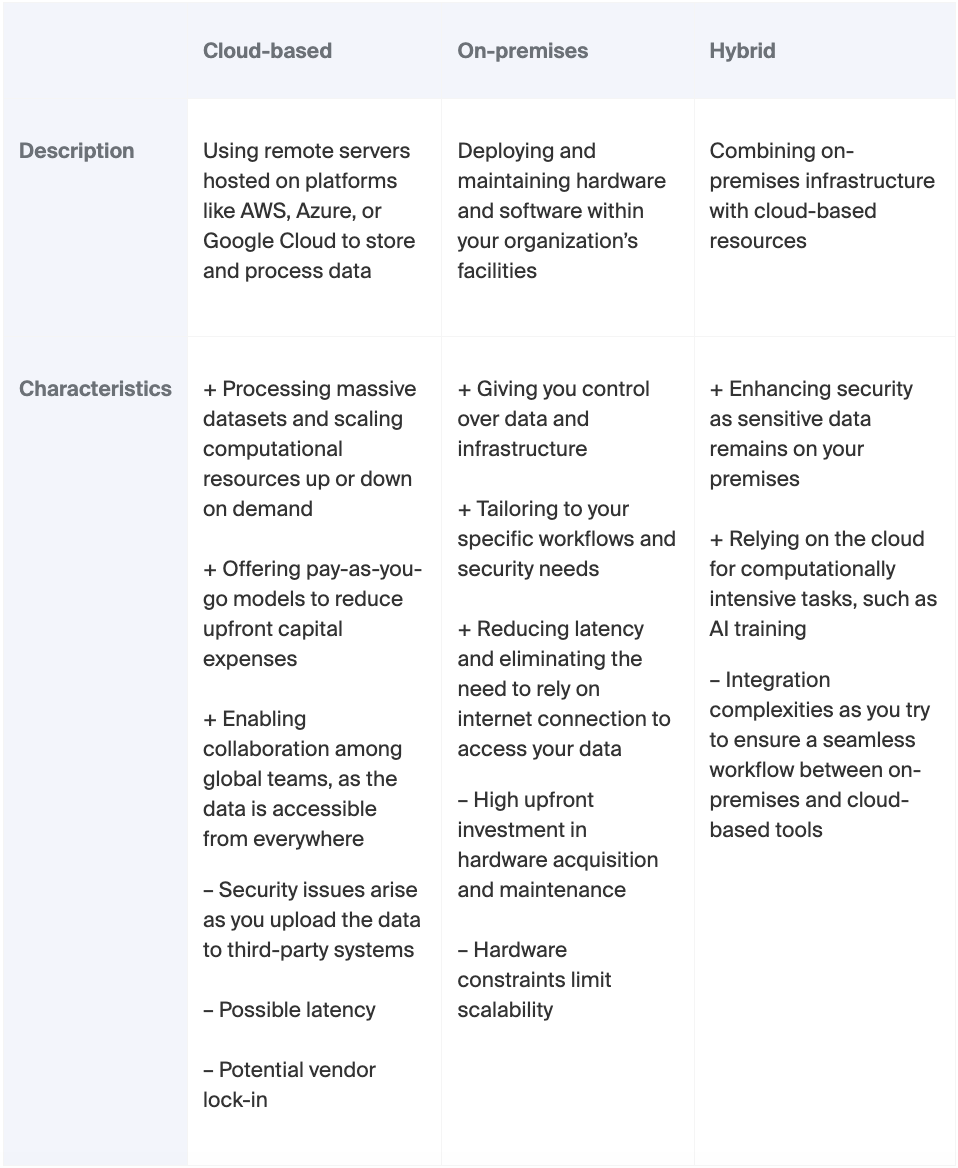
زیرساخت و مقیاسپذیری
پردازش دادههای اومیکس نیازمند قدرت محاسباتی و ظرفیت ذخیرهسازی قابل توجهی است که زیرساخت را به یک عامل کلیدی تبدیل میکند. راهحلهای مبتنی بر ابر مقیاسپذیری و انعطافپذیری را ارائه میدهند و تیمها را قادر میسازند تا مجموعهدادههای بزرگ را مدیریت کرده و مدلهای هوش مصنوعی نیازمند به محاسبات بالا را اجرا کنند. زیرساختهای محلی به شما کنترل کامل بر دادهها و الگوریتمهایتان را میدهند اما نیازمند سرمایهگذاری اولیه قابل توجهی هستند. رویکرد ترکیبی به شما امکان میدهد هر دو گزینه را ترکیب کنید.
مقیاسپذیری همچنین شامل طراحی فرآیندهایی است که میتوانند با افزایش حجم دادهها و نیازهای تحلیلی در حال تکامل سازگار شوند. یکی از نمونهها استفاده از کانتینرسازی - بستهبندی یک برنامه و تمام وابستگیهای آن در یک کانتینر - و ابزارهای ارکستراسیون، مانند داکر و کوبرنتس، برای مدیریت استقرار و مقیاس این کانتینرها است.
اگر تصمیم به همکاری با ITRex بگیرید، ما به شما کمک خواهیم کرد تا بین رویکردهای مختلف استقرار، با در نظر گرفتن عواملی مانند الزامات امنیتی دادهها، زمان تاخیر و کارایی هزینه بلندمدت، انتخاب کنید. تیم ما همچنین در مورد گزینههای کانتینرسازی و ارکستراسیون به شما مشاوره خواهد داد.
هزینههای عملیاتی
پیادهسازی یک سیستم هوش مصنوعی برای تجزیه و تحلیل دادههای اومیکس شامل هزینههای اولیه و مداوم است. سازمانها باید برای هزینههای زیر بودجهبندی کنند:
- دستیابی به دادههای با کیفیت بالا و پیشپردازش آنها
- فراهم کردن فضای ذخیرهسازی داده
- ساخت یا مجوزدهی مدلهای هوش مصنوعی
- منابع محاسباتی و مصرف انرژی
- نگهداری زیرساخت مورد نیاز یا پرداخت هزینههای استفاده به یک ارائهدهنده ابری
- آموزش کارکنان شما
خدمات ابری، در حالی که به نظر گزینه ارزانتری میآیند، اگر بهدقت مدیریت نشوند، ممکن است منجر به هزینههای غیرمنتظره شوند. همین امر در مورد الگوریتمهای تجاری آماده هوش مصنوعی صدق میکند. در حالی که توسعه یک مدل هوش مصنوعی از ابتدا نیازمند سرمایهگذاری اولیه بزرگتری است، هزینههای مجوزدهی برای ابزارهای آماده میتوانند بهسرعت انباشته شده و افزایش یابند، بهویژه با گسترش عملیات شما.
برای ارائه یک نمای کلی دقیقتر از گزینههای قیمتگذاری، تحلیلگران ما راهنماهای جامعی را در مورد هزینههای مرتبط با هوش مصنوعی، هوش مصنوعی مولد، یادگیری ماشین و پیادهسازی راهحل تحلیل دادهها گردآوری کردهاند.
یک تیم توسعه نرمافزار سفارشی میتواند یک ابزار هوش مصنوعی را از ابتدا بسازد که نیازهای خاص شما را برآورده کند، در حالی که هزینههای غیرضروری مجوز را حذف میکند. در ITRex، ما رویکرد چابک را دنبال میکنیم و به تدریج راهحل را توسعه میدهیم. این به شما امکان میدهد تا مراحل پروژه را بررسی کرده و بازخورد خود را ارائه دهید تا نتایج نهایی دقیقاً همان چیزی باشد که شما نیاز دارید.
نتیجهگیری
تجزیه و تحلیل دادههای اومیکس حوزهای با پتانسیل دگرگونکننده برای زیستشناسی، پزشکی و فراتر از آن است. چالشهای مرتبط با حجم و پیچیدگی دادهها با رویکردهای سنتی چالشبرانگیز هستند.
همانطور که در این مقاله توضیح داده شد، هوش مصنوعی با ارائه راهحلهایی برای مدیریت ابعاد بالا، ادغام دادههای ناهمگون، پرداختن به نویز و اطلاعات از دست رفته، افزایش دقت و کارایی و بهبود قابلیت تفسیر، راه را برای تجزیه و تحلیل و ادغام مؤثر دادههای اومیکس هموار میکند.
بهکارگیری هوش مصنوعی در تجزیه و تحلیل دادههای اومیکس یک گام حیاتی بهسوی بهرهگیری کامل از پتانسیل دادههای اومیکس و پیشبرد دانش بیولوژیکی برای بهبود سلامت انسان است. اگر به دنبال شریکی برای راهاندازی پروژه دادههای اومیکس مبتنی بر هوش مصنوعی خود هستید، همین امروز با متخصصان ما در ITRex تماس بگیرید.